

Butler-Run #3 detail, 2022
Black Corpus
- Year: 2018... ongoing
- Team: Ayodamola Tanimowo Okunseinde, Yvette King, Nicole Lloyd Freeman, Jeharrah Pearl, Amir Denzel Hall, Nikita R Huggins
-
Role:
Concept, Design, Technology
Black Corpus is a research laboratory that seeks to address bias in machine learning systems while creating tools and artworks that make machine learning environments more accessible. Focused on Black and African Diasporic language, text, vernacular, and writing, the collective not only produces and analyzes alternative machine learning datasets but also creates related artworks that are meaningful and expressive. Some of the methodology implemented include identifying unique modes of communication internal to Black and African Diasporic communities, analysis of language structures and syntax, the use of machine learning tools to attempt to pull meaning from text, and the creation of digital and physically-based artworks that promote diversity in the machine learning field. The collective aims also to teach machine learning tools and methods to underrepresented communities, develop related art & technology curricula, and archive datasets and assets that may be utilized as research material.
Machine learning (ML) uses statistical techniques to give computers the ability to "learn" from data and thus improve performance on a specific task without being explicitly programmed. Though this field is growing exponentially, there exists a lack of representation of BIPOC groups in the field. This lack of representation in the programming of ML algorithms, collection of datasets, and development of ML-based products are deleterious and diminishes the potential positive social impact, efficacy, and economic impact of the field. This lack of diversity additionally has the potential to manifest itself in products and systems that are biased and dangerous to underrepresented groups by not fully taking these groups into account.
Iyapo Repository & Unbroken Meaning @ playtest, The Library of Congress, 2018

Epiphenomenon_01 @ Sorry, Niether, The Naughton Gallery 2021
Neons ⬆️
- 2022
The Black Corpus Neons endeavors to physicalize quotations obtained from the machine’s attempt to synthesize its “understandings” of texts by Black theorists into new creative language about Blackness. The works play on the popular genre of neon signs to elucidate the generative potential of collaborations between Black theorists, artists, and machine learning systems in theorizing Blackness. Utilizing the Generative Pre-trained Transformer 2 (GPT-2) algorithm, the works of Frantz Fanon, James Baldwin and Octavia Butler were collated as input training data to produce their respective language models. Once created, the models can be asked questions related to race, gender, and other pressing social issues, the output of which are produced as artworks. Fanon - Run #2 and Butler - Run #3, represent two such outputs that illuminate hidden SUBTEXT about Blackness within the works of these Black authors.

Butler - Run #3, 2022 - White Neon, ~42"x28"

Fanon - Run #2, 2022 - Green Neon, ~44"x36"
Butler - Run #3 - detail, 2022 - White Neon, ~42"x28"

Fanon - Run #2 - detail, 2022 - Green Neon, ~44"x36"

Butler - Run #3, Fanon - Run #2
Epiphenomenon ⬆️
- 2021
Epiphenomenon_01 takes Michelle Wright's notion of epiphenomenal time as a provocation to think of Black temporality and existence removed from the linear confines of the Atlantic Slave Trade. The piece attempts to distort prosaic representations of time-space, warping them, to argue that the time-space of Blackness is not static nor linear but instead a discursive, ever shifting ecosystem that is informed by and subsequently molds notions of race, politics, and memory.
The Epiphenomenon_01 prismatic cube exists as an artifact of epiphenomenal time-space. It invites participants to reconfigured engraved acrylic sheets into a myriad of patterns that never resolve into any particular objective perspective. Furthermore, using Wright's Physics of Blackness (2015) as a source, machine learning generated text engraving punctuates the etched acrylic sheet to suggest discursive reading of the text, too, speaks to the intractability of Black existence in time-space.
Epiphenomenon_01, created by the Black Corpus collective, can be viewed from all angles. Allowing rays of light to penetrate the artifact projects and reflects trace patterns of visual information that casts positive and negative shadows, further elucidating the significant yet elusory nature of the work's concept.

Epiphenomenon_01, 2021 - Etched Acrylic, 10"x10"10"

Epiphenomenon_01, 2021 - Etched Acrylic, 10"x10"10"

Epiphenomenon_01, 2021 - Etched Acrylic, 10"x10"10"

Epiphenomenon_01, 2021 - Etched Acrylic, 10"x10"10"
Unbroken Meaning ⬆️
- 2018
Unbroken Meaning is a Black Corpus project that investigates the ability of current speech-to-text algorithms to understand African Diaspora-derived Creole, Pidgin, and Broken English. It seeks to demonstrate the bias of these algorithms while developing new algorithms that are better suited to recognize phrases and languages of these communities. Additionally, it seeks to create suitable text-to-speech methods for proper computer pronunciation of these languages. Finally, Unbroken Meaning collects audio samples of phrases and speech patterns to serve as a method of archiving the vocabulary and grammar of selected communities. We were invited by the Library of Congress to showcase Unbroken Meaning at the Playtest conference. Playtest brought together a diverse group of thought leaders and creative technologists working at the intersection of virtual reality, emerging media, and humanities research.

Unbroken Meaning, 2018 - Mac Mini, Computer Monitors

Unbroken Meaning, 2018 - Mac Mini, Computer Monitors

Unbroken Meaning @ playtest - The Library of Congress, 2018
Corpora ⬆️
- 2022
Corpora is the collection of datasets and algorithmic models developed by Black Corpus. The collection is available for use by artists, educators, and researchers of all kinds interested in promoting the Black Corpus agenda. Included in Corpora are ML language models generated from the individual and collective works of authors such as W.E.B. Du Bois, Octavia Butler, James Baldwin, and more.

Corpora, 2022 - GPT-2, Raspberry Pi, Raspberry Pi Monitor

Corpora - Baldwin, 2022 - GPT-2, Raspberry Pi, Raspberry Pi Monitor

Corpora - Delany, 2022 - GPT-2, Raspberry Pi, Raspberry Pi Monitor

Corpora - Fanon+Baldwin+Butler, 2022 - GPT-2, Raspberry Pi, Raspberry Pi Monitor
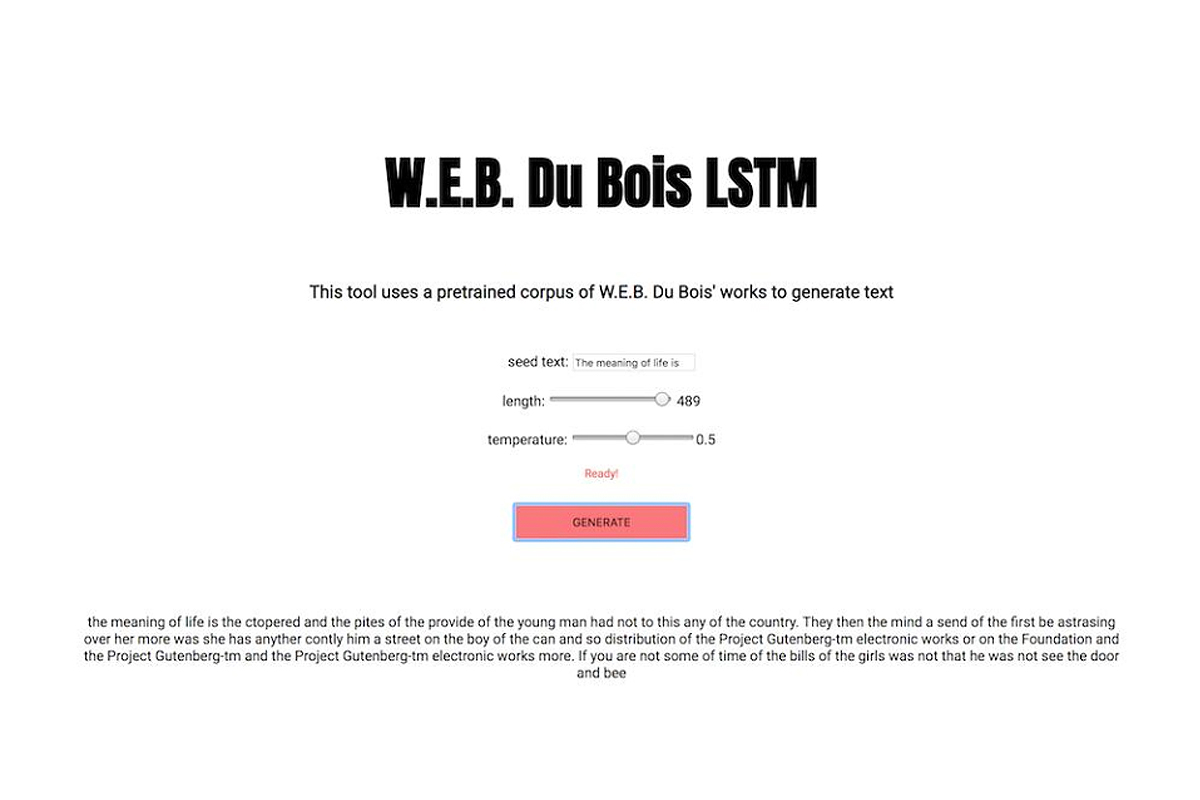
W.E.B. DuBois LSTM, 2019 - Web app
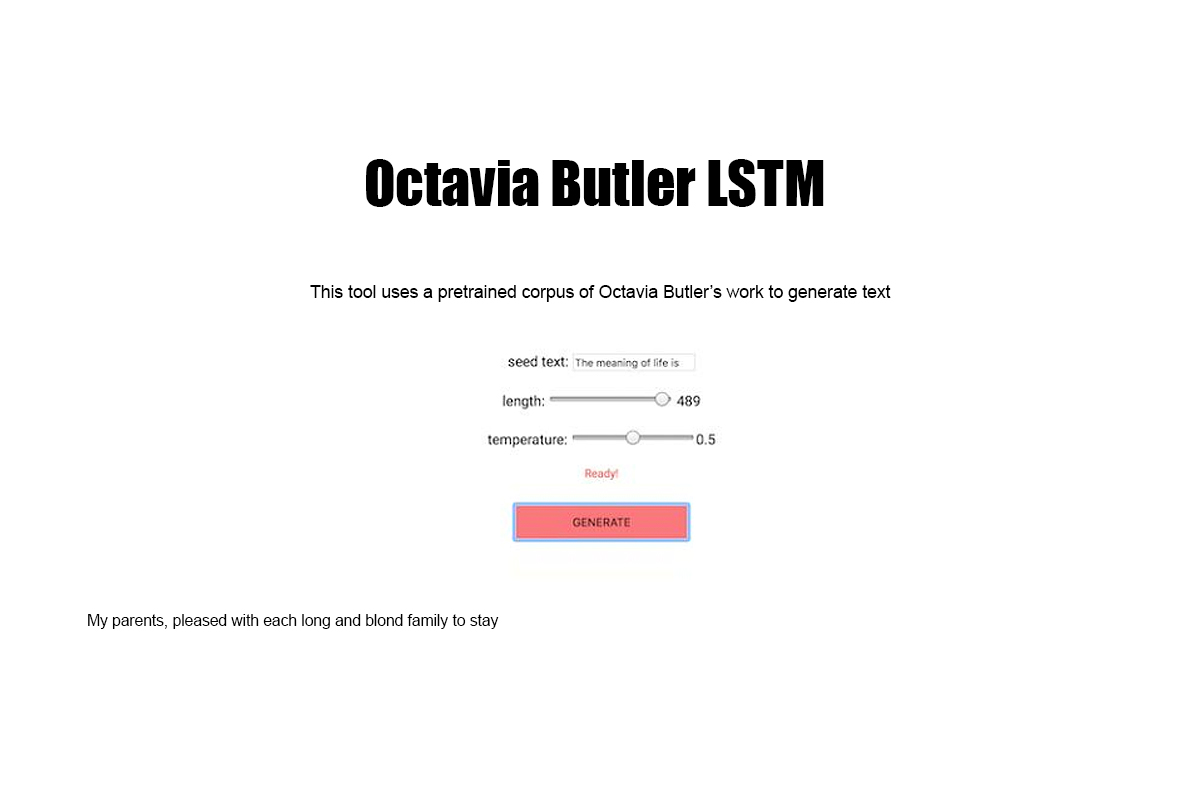
Octavia Butler LSTM, 2019 - Web app